Cozy Computer

![]()
 <——- Find me (Patrick McCarver) (they/he)
<——- Find me (Patrick McCarver) (they/he)
Bash autocompletion and removing weirdly named files using inodes on Ubuntu 792 words (4 min)
Recently I was updating my resume and downloaded a pdf file named Resume several times.
patrick@nara:~/Downloads$ ls | grep Resume
Resume(1).pdf
Resume(2).pdf
Resume(3).pdf
Resume.pdf
Someone - maybe Ubuntu’s file manager (GNOME Files) - decided that my downloaded files were duplicates and renamed the downloaded files with parenthesis (Resume(1), Resume(2), Resume(3)). I needed to remove the duplicates.
Normally I would let bash autocompletion find the file: rm Resume(1<TAB>. But my autocompletion was not able to complete - it couldn’t find the file named Resume(1).pdf.
I tried rm Resume(1) and got an error:
bash: syntax error near unexpected token `('
Oh! The parenthesis need to be escaped:
rm Resume\(1\).pdf
You remove files with special characters in them by escaping the special characters.
I could have used * for the problem characters and the -i flag (interactive removal) to cycle through all of the Resume files and choose which ones to delete:
rm -i Resume*.pdf
But some questions remain:
- Who is in charge of the bash autocompletion and why did it fail?
- What if the file has a lot of special characters and we don’t want to escape them all or build a long regular expression to find the file?
Bash autocompletion
The complete command is used to set what program deals with autocompletion for a bash command. Type complete to see the entire list (here’s part of mine):
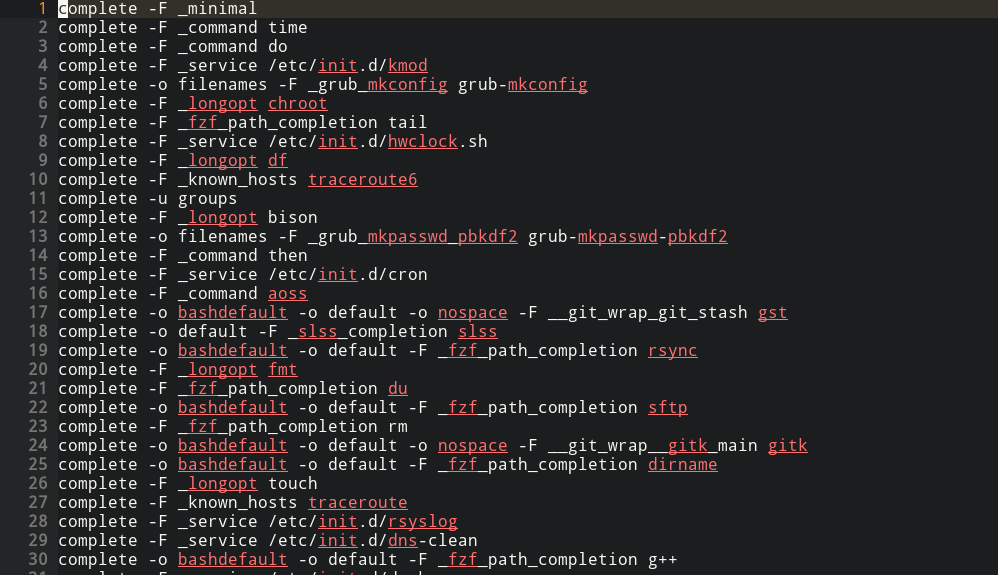
Let’s see what programs provide autocompletion for removing files with complete | grep rm:
complete -F _fzf_path_completion rm
complete -F _service /etc/init.d/apparmor
complete -F _fzf_dir_completion rmdir
I have fzf (fuzzy find) installed, apparently it has taken over autocompletion for the rm command.
I can verify this by running set -x - for debugging Bash scripts - and then attempting to autocomplete by typing Resume<TAB>:

Everything after the + is fuzzy find related code.
Although I am not sure how to make fuzzy find behave with non-escaped special characters, fuzzy find does have a nice workaround. Typing **<TAB> will allow interactive completion using fuzzy find. During the search, you won’t have to escape special characters:
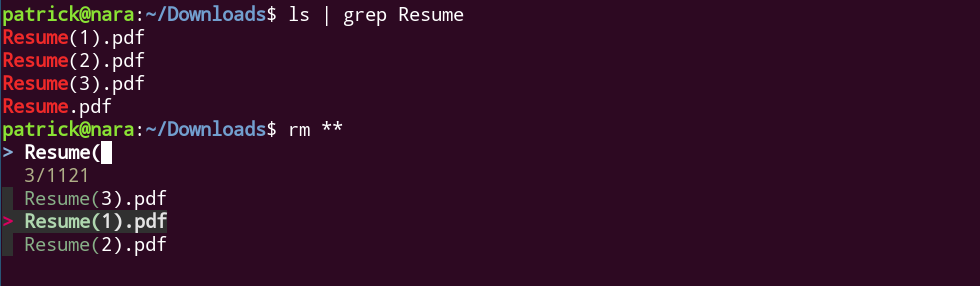
Fuzzy find escapes the special characters automatically after you select the file:
rm Resume\(1\).pdf
There’s a lot more to learn about Bash autocompletion. I’ll try to explore this topic more in the future.
Finding and removing files using inodes
Suppose I have an annoyingly named file:
touch ~/Pictures/\(\(\*\*\*what\(is\)\(t\)\(h\)\(i\)\(s\)\(\(annoying\)\(file\)\(name\)****.png
When I created the file my system actually wrapped it in quotes: '((***what(is)(t)(h)(i)(s)((annoying)(file)(name)****.png'. This makes it very easy to select and process with autocompletion.
If it hadn’t done that though, like with Resume(1).pdf above, I might want another way to select the file.
You can select a file using its inode - the data structure that Linux uses to represent files and directories. Every file and directory has an index number - a unique number that Linux uses to identify the file.
To see the index number for the file use ls -i:
1969088 ((***what(is)(t)(h)(i)(s)((annoying)(file)(name)****.png
The find command can be used to locate a file by inode with the -inum flag. The -maxdepth 1 flag ensures you only find files in the current directory (which is important because other other mounted filesystems might have unrelated files with the same inode). The -type f flag looks for regular files:
find . -maxdepth 1 -type f -inum 1969088
The command returns the file name: ((***what(is)(t)(h)(i)(s)((annoying)(file)(name)****.png.
After confirming that find found the right file, use the -delete flag to remove the file:
find . -maxdepth 1 -type f -inum 1969088 -delete
Some other tools for dealing with duplicate files
A few popular tools for finding and removing duplicate files on Linux:
© Patrick McCarver
![]() <---- Want to become a better programmer?
Join the Recurse Center!
<---- Want to become a better programmer?
Join the Recurse Center!
Email icon by Icons8